Query engines for Agents
We’re building a query engine, so I’ve been thinking about the difference between query engines built for humans and those specially made for agents. Regardless of the differences, I think two things will be the same: speed will be important, and it will, of course, use SQL.
So what’s the difference? A big part is how queries are generated. Humans and agents operate at very different speeds and under different constraints. Humans are slow. They have a question, perform a query, look at the results, tweak it, and maybe come back to it later. Once they have an answer, they can carry that information forward without having to go back to the results again. A lot of tooling is built around that rhythm.
On the other hand, agents are fast and repetitive. They issue lots of small queries, chain them together, and reuse intermediate results. As a result, queries are tightly coupled with the reasoning process.
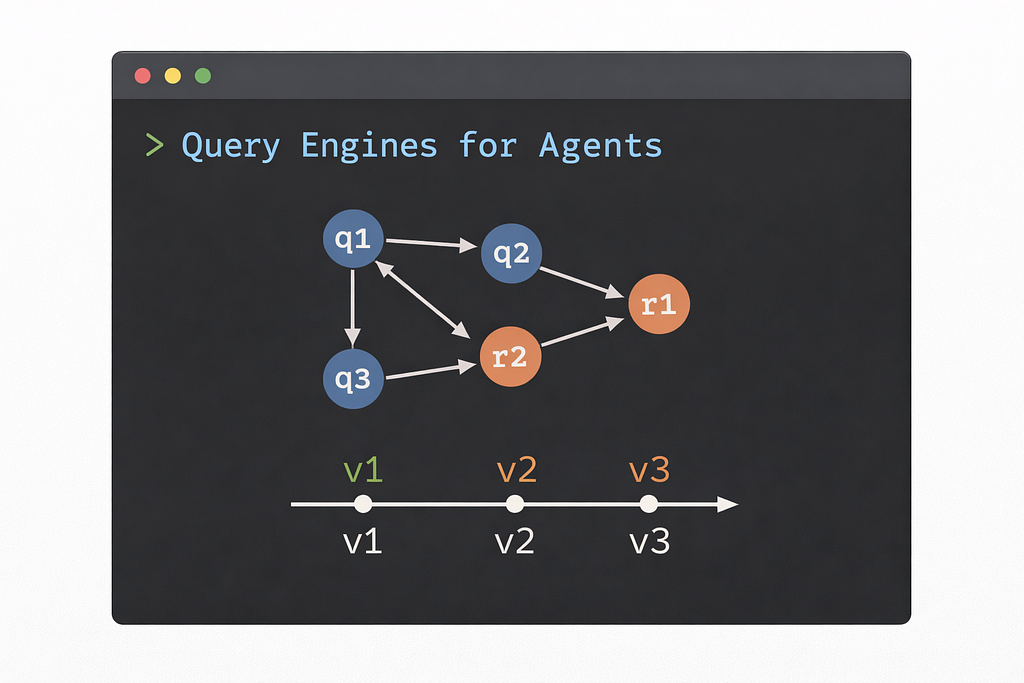
Execution structure
Agent queries are rarely independent. They form a dependency graph, where the output of one step feeds directly into the next, and intermediate results are reused across branches of a larger plan.
Humans can hold context in their heads, while agents need systems to help manage that context.
Humans can analyze by skimming data and building an intuitive sense of what they are looking at. Agents need to replay what they’ve done and compare results. I think version control presents an internal mental model for how agents can keep track of change.
Durability and context loss
What this means is that if the results are not durable, context is lost. When intermediate results disappear or change across runs, the agent loses its place. The reasoning process becomes non-replayable, and small inconsistencies can cascade across an entire workflow. I wrote about that here.
Latency amplification
Agents are also more sensitive to latency. A human can tolerate a few seconds of delay, but an agent may have dozens of parallel requests going, and having an answer block can interrupt a much larger workflow. Latency compounds in agent workflows. A single slow query can stall dozens of dependent steps, turning tail latency into a dominant failure mode rather than a minor inconvenience.
The question that looms large over this topic is “will OpenAI solve this?” and the answer is: yes, but it doesn’t matter. There will be better models, but there will also be more data, and those new models will likely be interacting with more data sources, not fewer.
What does that interface look like?
Originally published on Medium.