Why Agents Need Version Control for Data
In the early days, developers could keep knowledge of the systems they worked on in their heads. You changed a file, ran a test, and moved on. That worked when codebases were relatively small.
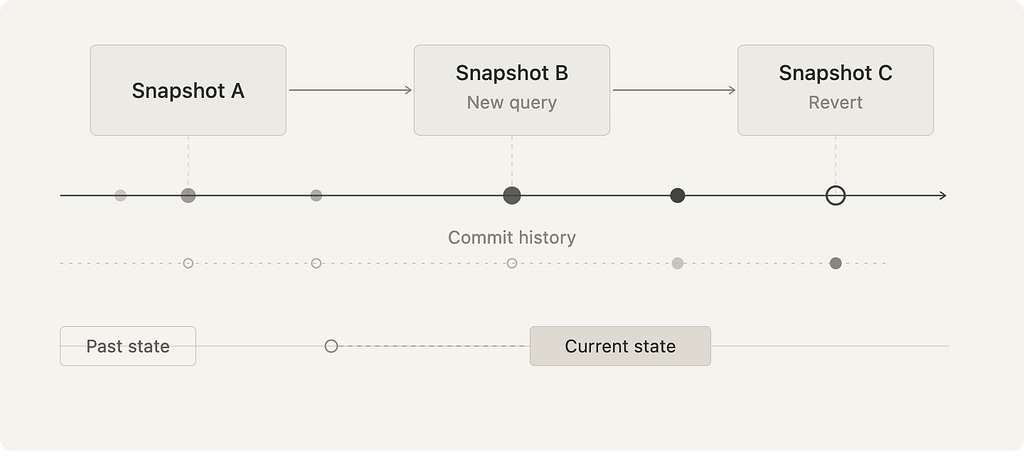
But as systems grew, that model broke. Once projects reach a certain size, you often need to understand how the system arrived at its current state. For example, to answer basic questions like “when was this bug introduced?”, you need a way to track changes over time.
That’s why version control is so important. Version control creates a durable record of every change you make. This allows you to see how the codebase looked at any point in time, branch off at any snapshot, and then rejoin the main codebase whenever you are ready.
Git pushed this idea further by encouraging even smaller steps, making it easier to work across branches. Git itself came out of necessity, as Linus Torvalds struggled to coordinate one of the largest globally distributed teams on earth. This basic idea has allowed us to build more ambitious systems and allowed hyper-collaborative tools like GitHub to exist.
Agents are now running into a similar situation as developers, but through the lens of data.
Agents’ context windows act as working memory. An agent pulls in a few tables, runs some queries, forms a local understanding of the problem, answers questions, and when the task ends, that context disappears.
This makes it hard for agents to build on earlier work. When an agent wants to explore a different path, it often repeats the same queries and recomputes the same results because there is no durable record of what it already did. The work looks iterative, but much of it is being recomputed every time. Now imagine managing this when the work is exploratory.
The number of combination explodes!
This is where the version control analogy becomes useful. Version control is not only about collaboration. It is also about maintaining an audit trail of state.
We have this concept for code, and even for Docker containers capturing the state of a system, but we are still early on the data side. Today, agents assemble tables and queries and work within limited scopes, but it’s all ephemeral. Unless it is a specific project requirement, teams are not building agents with durable, re-playable data, at the level of individual sessions.
As agents take on more open-ended tasks, managing context windows will be a challenge, and properly managing the evolution of context will matter as much as the models we use.
Originally published on Medium.